 在马斯克的领导下,我们见证了推特的一次又一次改革。上周末,马斯克再次带来了让人惊讶的消息:推特被限流了。那么,这次推特的变化究竟意味着什么,尤其是对于那些依赖推特数据的大模型,比如OpenAI的GPT-4,会有什么影响?从6 月 30 日起,推特用户陆续发现无法在未登录状态下查看推文。对此,马斯克在推文中回应称,这是为应对「数据掠夺」而采取的“临时紧急措施”;“数百个组织(也许更多)正在极其活跃地抓取 推特数据,导致影响了真实用户的体验”。这并不是推特近几个月来遇到的第一个技术问题,也不是第一个为解决问题而设计的非常规解决方案。本周早些时候,推特开始限制未登录帐户的用户通过桌面和移动设备上的网络浏览器访问推文和个人资料。而除了自己声称的“限制第三方抓取推特数据”这一理由外,马斯克还转发了一位高仿号的推文,内容是:“我设置推文浏览量限制的原因是因为我们都是‘推特成瘾者’,每天大家都恍惚于网络世界,我这是在为世界做一件好事。”
在马斯克的领导下,我们见证了推特的一次又一次改革。上周末,马斯克再次带来了让人惊讶的消息:推特被限流了。那么,这次推特的变化究竟意味着什么,尤其是对于那些依赖推特数据的大模型,比如OpenAI的GPT-4,会有什么影响?从6 月 30 日起,推特用户陆续发现无法在未登录状态下查看推文。对此,马斯克在推文中回应称,这是为应对「数据掠夺」而采取的“临时紧急措施”;“数百个组织(也许更多)正在极其活跃地抓取 推特数据,导致影响了真实用户的体验”。这并不是推特近几个月来遇到的第一个技术问题,也不是第一个为解决问题而设计的非常规解决方案。本周早些时候,推特开始限制未登录帐户的用户通过桌面和移动设备上的网络浏览器访问推文和个人资料。而除了自己声称的“限制第三方抓取推特数据”这一理由外,马斯克还转发了一位高仿号的推文,内容是:“我设置推文浏览量限制的原因是因为我们都是‘推特成瘾者’,每天大家都恍惚于网络世界,我这是在为世界做一件好事。”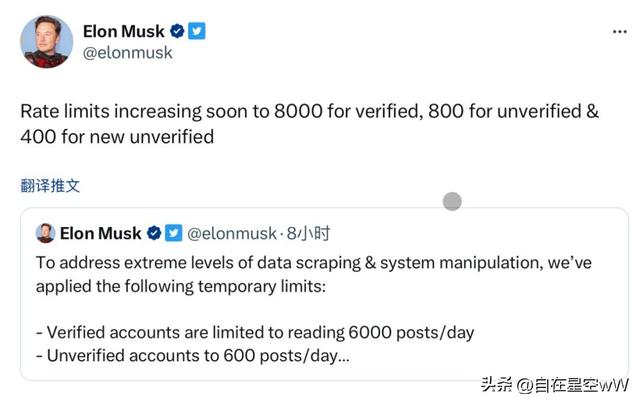 仅仅一天之后,马斯克进一步宣布了对于已登录用户浏览量的所谓“临时限制”:新注册未认证用户、现有未认证用户和已认证用户每天分别最多能浏览 300、600 和 6000 条推文,但将很快“提高”到 400、800 和 8000 条。马斯克的决策转变是否预示着推特的商业模式正在发生根本性的改变,寻求以更高效的方式从社交媒体平台上获得收益,还是说他对数据的未来有着不一样的洞察,看到了大众还未意识到的东西?
仅仅一天之后,马斯克进一步宣布了对于已登录用户浏览量的所谓“临时限制”:新注册未认证用户、现有未认证用户和已认证用户每天分别最多能浏览 300、600 和 6000 条推文,但将很快“提高”到 400、800 和 8000 条。马斯克的决策转变是否预示着推特的商业模式正在发生根本性的改变,寻求以更高效的方式从社交媒体平台上获得收益,还是说他对数据的未来有着不一样的洞察,看到了大众还未意识到的东西?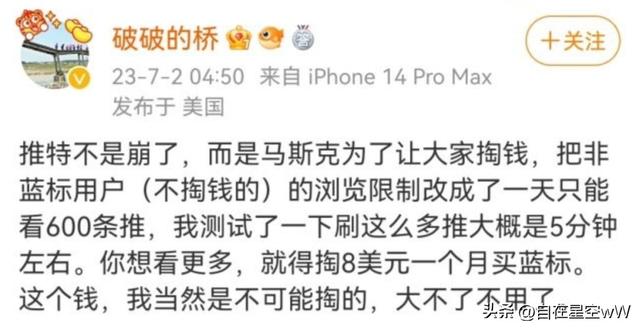 想用数据训练大模型?可以,但要先交钱此前,马斯克曾多次指责人工智能公司抓取推特数据训练大语言模型的做法。虽然马斯克没有透露谁在抓取推特的数据,也没有说明这个问题持续了多长时间和详细解释系统如何被操纵。但在此前,马斯克曾对推特上的数据抓取表示担忧,并暗示他可能会对不良行为者采取行动。今年4月,他就对微软“非法”使用推特数据表示愤怒,显然是指微软与人工智能公司OpenAI的合作。OpenAI在“来自互联网的大量不同文本数据集”上训练人工智能模型,马斯克表示,“他们非法使用推特数据进行模型训练,这次诉讼时间到了。”在过去,大型数据集通常来自于公开可用的信息,如推特等社交媒体的推文、Wikipedia的文章、超大型公开数据集Common Crawl等等。然而,随着数据隐私的问题越来越受到关注,以及各大公司的政策改变,未来是否还能继续使用这些数据来源呢?在推特更改它的政策之前,国外知名论坛Reddit也宣布了类似的策略。今年4月,Reddit决定对其API的使用开始收费。这并不是一项全面的政策改变,Reddit的API仍然对希望构建帮助人们使用Reddit的应用和机器人的开发者以及希望出于严格的学术或非商业目的研究Reddit的研究者免费开放。不过,对Reddit进行数据抓取并且“不将任何价值回馈给用户”的公司将需要付费。
想用数据训练大模型?可以,但要先交钱此前,马斯克曾多次指责人工智能公司抓取推特数据训练大语言模型的做法。虽然马斯克没有透露谁在抓取推特的数据,也没有说明这个问题持续了多长时间和详细解释系统如何被操纵。但在此前,马斯克曾对推特上的数据抓取表示担忧,并暗示他可能会对不良行为者采取行动。今年4月,他就对微软“非法”使用推特数据表示愤怒,显然是指微软与人工智能公司OpenAI的合作。OpenAI在“来自互联网的大量不同文本数据集”上训练人工智能模型,马斯克表示,“他们非法使用推特数据进行模型训练,这次诉讼时间到了。”在过去,大型数据集通常来自于公开可用的信息,如推特等社交媒体的推文、Wikipedia的文章、超大型公开数据集Common Crawl等等。然而,随着数据隐私的问题越来越受到关注,以及各大公司的政策改变,未来是否还能继续使用这些数据来源呢?在推特更改它的政策之前,国外知名论坛Reddit也宣布了类似的策略。今年4月,Reddit决定对其API的使用开始收费。这并不是一项全面的政策改变,Reddit的API仍然对希望构建帮助人们使用Reddit的应用和机器人的开发者以及希望出于严格的学术或非商业目的研究Reddit的研究者免费开放。不过,对Reddit进行数据抓取并且“不将任何价值回馈给用户”的公司将需要付费。
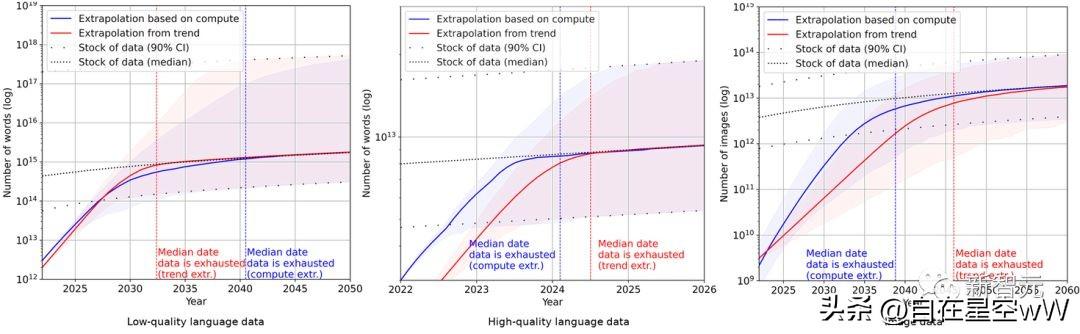
结果表明,高质量的语言数据存量将在 2026 年耗尽,低质量的语言数据和图像数据的存量将分别在 2030 年至 2050 年、2030 年至 2060 年枯竭。这意味着,如果数据效率没有显著提高或有新的数据源可用,那么到 2040 年,模型规模的增长将会放缓。
 写在最后虽然数据增长放缓的长期趋势是不可避免的,但数据使用效率的提升可能成为解决问题的最佳途径,未来大模型有可能并不需要更多数据就能实现同等的性能,单纯拼参数量的时代也终将结束。近年来,无监督学习取得了一定的突破,允许模型使用少量标注数据和大量未标注数据来针对多项任务进行微调,无监督模型也被证明能够为未标注数据生成有价值的伪标签。而多模态模型的快速发展更是让模型能够对同一数据从不同角度进行考虑,实现了比单一模态更好的性能。同时,随着科技的进一步发展,物联网、自动驾驶等以前未曾有过数据积累的行业也在产生新的数据种类,各类传感器的使用也在让数据的获取变得更加简单,这些行业有望实现数据量的指数级增长,也将为大模型训练提供更多的数据来源。
写在最后虽然数据增长放缓的长期趋势是不可避免的,但数据使用效率的提升可能成为解决问题的最佳途径,未来大模型有可能并不需要更多数据就能实现同等的性能,单纯拼参数量的时代也终将结束。近年来,无监督学习取得了一定的突破,允许模型使用少量标注数据和大量未标注数据来针对多项任务进行微调,无监督模型也被证明能够为未标注数据生成有价值的伪标签。而多模态模型的快速发展更是让模型能够对同一数据从不同角度进行考虑,实现了比单一模态更好的性能。同时,随着科技的进一步发展,物联网、自动驾驶等以前未曾有过数据积累的行业也在产生新的数据种类,各类传感器的使用也在让数据的获取变得更加简单,这些行业有望实现数据量的指数级增长,也将为大模型训练提供更多的数据来源。

花粉社群VIP加油站
关于作者

猜你喜欢





































